A production tool that runs 9 LLMs across 5 providers in parallel to evaluate a stock, then makes them debate when they disagree — every answer grounded in SEC filings.
Understanding whether a company is actually financially healthy is gated by time and expertise.
A single 10-Q filing is dozens of pages of dense numbers and legalese; reading enough of them to form an opinion takes hours and assumes you already know what to look for. The easy shortcut — asking one LLM — trades one slow process for one biased opinion. Models hallucinate numbers, cherry-pick data points, and bias their own conclusions. You can't tell which it's doing.
Agora Financials makes nine LLMs across five providers analyze the same filings in parallel, then forces them to debate the metrics they disagree on. Consensus from disagreement instead of a single opinion you can't verify.
One-Minute Walkthrough
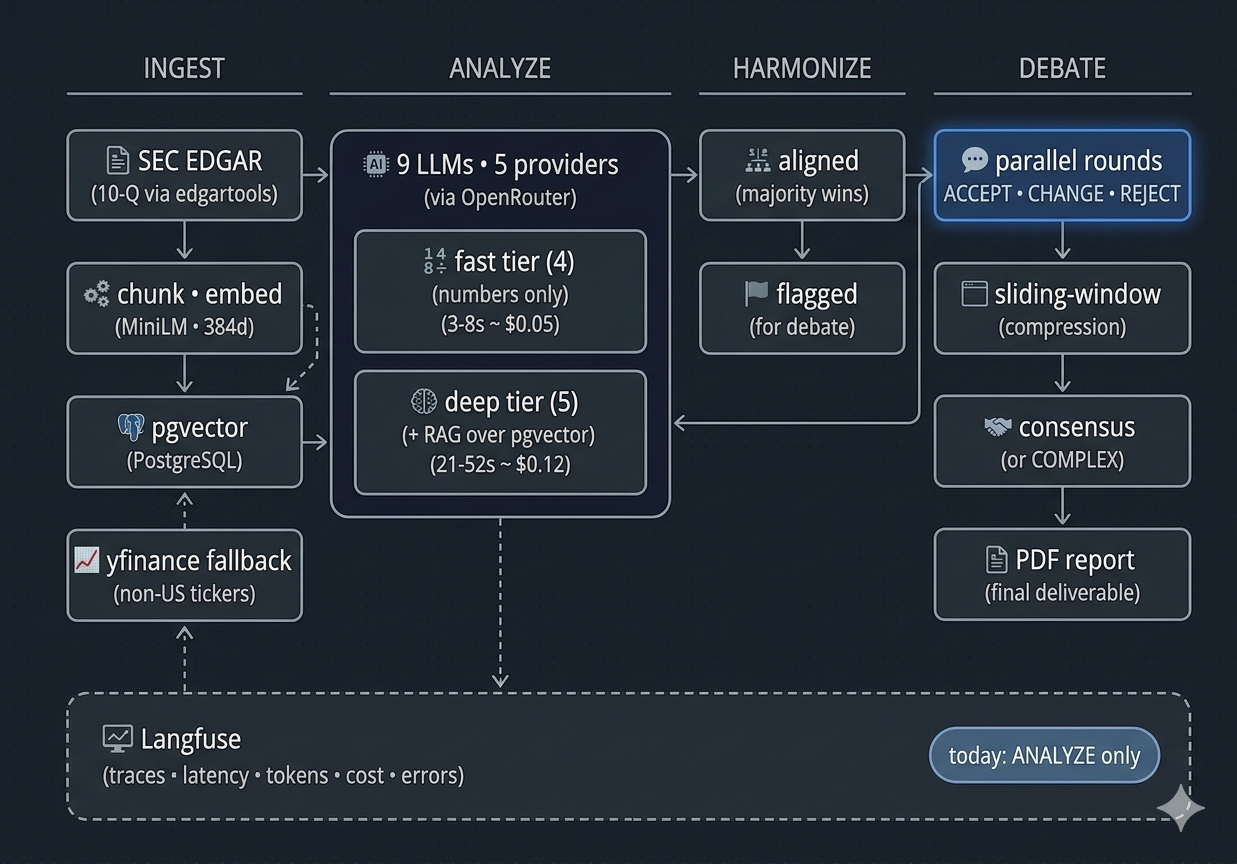
System Design
One FastAPI service, four phases: ingest → analyze → harmonize → debate. Each phase is its own endpoint and runs to completion before the next starts — the frontend orchestrates the chain, holds intermediate state, and renders progress per phase so the user sees the pipeline live.
Nine models run in parallel via asyncio.gather, all routed through OpenRouter for unified billing, with direct-provider fallback when OpenRouter degrades. pgvector holds the SEC filing embeddings in the same Postgres that holds app data — one database, not two.
Four design choices worth discussing
OpenRouter as the unified gateway, with direct-provider fallback. Five providers (xAI, OpenAI, Anthropic, Google, Mistral) behind one API key, one billing dashboard, one cost-reporting format. Each model call routes through OpenRouter first; if it fails or stalls, the same call retries directly against the provider's native endpoint. The cost is one extra network hop on the happy path; the gain is being able to add or swap a model via env var instead of an integration.
Two-tier model split — fast vs. deep, not cheap vs. expensive. The fast tier (four models, 3–8s, ~$0.05 per metric) gets the pre-formatted financial tables only. The deep tier (five models, 21–52s, ~$0.12–0.25 per metric) gets the same tables plus a retrieval tool over pgvector for qualitative context from MD&A and segment notes. The discovery worth stating: the quality jump is fast→deep, not deep→premium. Cheap models often skip the retrieval tool entirely no matter how the prompt asks them not to, so paying for "premium fast" loses to plain "deep."
Multi-round debate with sliding-window history compression. When models disagree on a metric, the debate orchestrator runs N rounds in parallel: each model defends, reviews others' arguments, and can ACCEPT / CHANGE / REJECT. Position changes are tracked structurally ("Claude: Good → Neutral"). The non-obvious part: debate history grows fast. A naive implementation pastes every prior response into every next prompt and token costs balloon — R5 was ~5× R2 in early tests. The fix is a sliding window: keep the last two rounds verbatim, summarize everything older into a compact table via one cheap mistral_fast call. R5 flattens to roughly R2 cost.
Three-layer caching, because every step in the pipeline costs money. Each expensive operation has a cache key in front of it.
SEC filings → chunks, keyed by (ticker, year, quarter) — re-ingesting a filing that's already in the chunks table skips the SEC download, the boilerplate filtering, the chunking, and the embedding API call.
Structured financial tables, keyed by (ticker, latest_filing_date) in a separate financial_statements table — the analysis route reads from here only, never re-hits SEC at request time.
LLM evaluations, keyed by (ticker, llm_model, latest_filing_date) in llm_financial_analysis — the full structured response stored as JSONB. At request time, the code splits the requested models into "already cached" and "needs to run" and only fires LLM calls for the latter. The same ticker re-evaluated against the same filing costs nothing in API spend.
Stack & Why
Four groups, each choice with a short note on the reasoning behind it.
Backend
Python 3.12 — every LLM provider (OpenAI, Anthropic, Google, xAI, Mistral) and orchestration library (LangChain, LangGraph) ships a first-class Python SDK. Async/await + Pydantic cover concurrency and types without a second language in the stack.
FastAPI — native async + Pydantic schemas means request/response models are defined once. Endpoint typing flows through to OpenAPI docs for free.
PostgreSQL with the pgvector extension + async SQLAlchemy 2.0 + Alembic — one database holds both relational data (users, watchlists, Stripe subscriptions) and the SEC filing embeddings. No second datastore to operate or sync.
Frontend
Next.js 16 + React 19 + TypeScript — SSR on the landing page for SEO, client-side state for the analysis flow. TypeScript end-to-end so the API contract is enforced from request to render.
dnd-kit for the watchlist — drag-and-drop reordering of tracked tickers without the legacy react-dnd footprint.
AI Layer
5 providers, 9 models via OpenRouter — xAI (Grok 4.1 Fast, Grok 4), OpenAI (GPT-5 Mini, GPT-5.1), Anthropic (Claude 3 Haiku, Claude Sonnet 4.6), Google (Gemini 2.5 Pro, deep tier only), Mistral (Small 3.2, Large 2411). One API key, one cost-reporting surface.
LangChain create_agent + LangGraph for tool-calling orchestration — each model becomes an agent with optional retrieval-tool access (deep tier only).
LangGraph's tool-call budget is set at invoke time via {"recursion_limit": 12} on .ainvoke(), not when the agent is created. Each tool call costs ~2 steps, so 12 steps caps deep models at ~5 retrievals per metric. Without this, some models skip the retrieval tool entirely — the prompt alone doesn't tell them they're budget-constrained.
pgvector RAG over SEC filings, with aggressive ingestion filtering — filings chunked with RecursiveCharacterTextSplitter at 2500 chars / 300 overlap, respecting markdown headers. A 53-pattern boilerplate blocklist strips SEC legalese, exhibit references, signatures, form headers, and forward-looking-statement disclaimers before chunking; anything under 100 characters is dropped. Embedded with OpenAI's text-embedding-3-small (1536 dims) via OpenRouter — same gateway as the LLM calls, so embedding spend rolls into the same cost surface. Retrieval at query time is cosine similarity with the <-> operator, top-8 chunks filtered by ticker.
Multi-round debate with sliding-window compression — the orchestrator keeps the last two rounds in full context and summarizes older rounds via one cheap mistral_fast call. Compression overhead is <0.5%; savings at five rounds are ~30%.
Gemini 2.5 Flash was pulled from the fast tier after a single evaluation produced 308 API calls and 794K input tokens because the model wouldn't stop calling the retrieval tool — $3.25 on one analysis versus ~$0.08 for the other fast models. Lesson: cheap stops being cheap when instruction-following breaks down.
WeasyPrint + Jinja2 for the PDF report — HTML/CSS templating to a downloadable evaluation. No separate report-rendering service to run.
Infrastructure & Auth
GitHub OAuth + Google OAuth via Authlib, JWT in HTTP-only cookies — XSS-safe, browser sends automatically, no password storage to maintain.
Anonymous rate-limiting via signed cookie — non-logged-in visitors get three analyses, tracked through a signed HTTP-only agora_session cookie. Zero DB rows until they sign up.
Stripe subscriptions + per-token top-ups — Free (70 tokens/mo), Hobbyist ($20/mo, 500), Investor ($49/mo, 1,200), Trader ($89/mo, 2,500). Webhooks are the source of truth: checkout.session.completed sets the tier, invoice.paid refills monthly, customer.subscription.deleted resets to free. Token costs are 2 (fast model) or 10 (deep model) per analysis.
edgartools for SEC ingestion, yfinance fallback for non-US tickers — edgartools handles US filings; yfinance fills in non-US data where SEC isn't available.
Docker + Railway — backend, frontend, Postgres on one platform. No Kubernetes complexity for a three-service app.
Evaluation
Observability is wired today on the heaviest route — the multi-LLM analysis — and the deeper evaluation layers (LLM-as-judge for structured output, tool use, debate consistency) are the next thing on the roadmap. The plan is to build them on the same Langfuse foundation that's already in place.
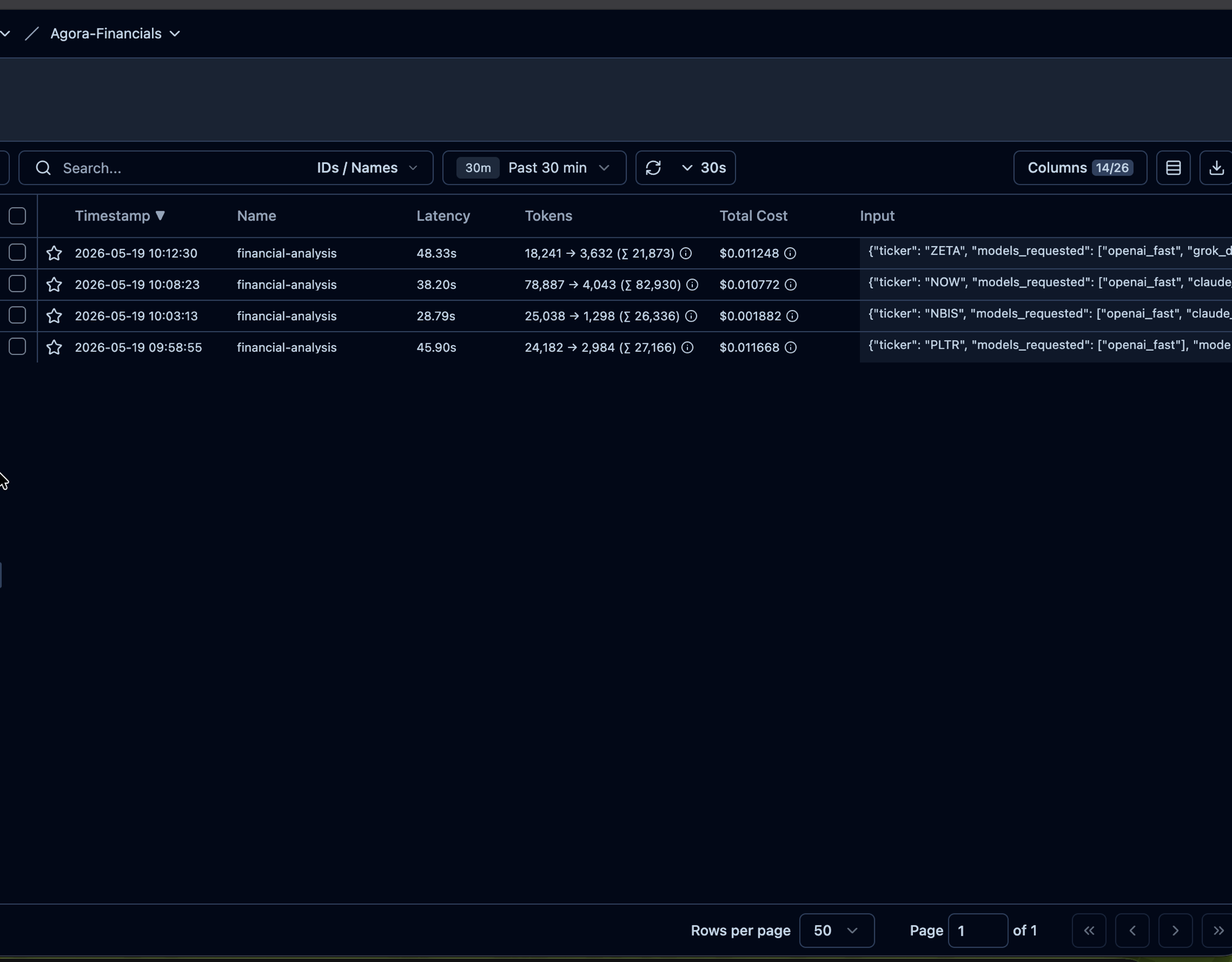
What's wired today — Langfuse on the analysis route
Every analysis request opens a Langfuse trace named financial-analysis. LangChain's CallbackHandler auto-captures each model call as a child span, with token counts and cost lifted from OpenRouter's response (the extra_body={"usage": {"include": True}} flag is on, so per-call cost is visible per provider). The trace_id is returned in the API response, ready for user-feedback scores to be attached later.
What that buys today: latency, token usage, cost, and errors per request, per model, queryable in one place.
Live Langfuse view — one trace per analysis, four recent requests across tickers ZETA, NOW, NBIS, PLTR.
Where it's going — three LLM-as-judge layers, on the same trace data
Each one builds on traces Langfuse is already collecting, so the work is judge prompts and Langfuse UI configuration, not new instrumentation. The three planned judges:
Structured-output schema compliance — does every model return the expected shape? Eight metrics, each with rating + reason + confidence. Catches schema drift across model upgrades.
Tool-use behavior — deep-tier models should hit the retrieval tool. The Gemini-Flash incident showed this can also fail in the other direction (a model calling the tool 78% of the time and never stopping). A judge that scores tool-call counts and patterns flags both failure modes systematically.
Debate consistency — position changes are already tracked structurally ("Claude: Good → Neutral"). The judge scores whether the new reasoning actually engages the counter-argument or just restates an opinion. Catches the case where models flip without justification.
Results
Live at agorafinancials.com. GitHub + Google OAuth, free tier available (three anonymous analyses, then 70 tokens/month signed up). Stripe subscriptions and per-token top-ups wired end to end through webhooks.
9 LLMs across 5 providers, evaluating 8 financial-health metrics per ticker. Four fast (3–8s, ~$0.05/eval) and five deep (21–52s, ~$0.12–0.25/eval) running in parallel under asyncio.gather, all behind OpenRouter with direct-provider fallback.
pgvector RAG over SEC filings. 10-Qs chunked, embedded with MiniLM-L6-v2, retrieved by ticker. Deep-tier models pull qualitative context (segment margins, MD&A commentary) that raw tables can't provide.
Multi-round debate with sliding-window compression. Flattens R5 token cost to roughly R2 levels — ~30% savings on five-round debates with minimal context loss.
Cost visibility per request via OpenRouter usage data flowing into Langfuse. Every model call, every provider, costed to the cent.
PDF reports via WeasyPrint + Jinja2 — downloadable evaluations rendered from HTML/CSS templates, no separate report service.
Roadmap
Extend Langfuse tracing to every route — analysis is wired; debate, harmonization, ingestion, and PDF generation are next. End-to-end traces let cost rollups and judges see the full request, not just the heaviest leg.
LLM-as-judge for structured output — verify every model returns the expected metric/rating/reason shape on every analysis. Catches schema drift before it ships to the report.
LLM-as-judge for tool use — flag deep-tier models that skip the retrieval tool, and also models that won't stop calling it. Both failure modes get measured systematically.
LLM-as-judge for debate consistency — score whether a model's position change actually engages the counter-argument. Position changes are tracked structurally today; quality of those changes isn't measured.
Year and quarter metadata filtering on retrieval — the chunks table already stores year, quarter, and filing_date per chunk, but retrieval today only filters by ticker. Adding them to the WHERE clause unlocks "the latest quarter only" or "the last fiscal year" as scoping options for the deep-tier prompts — one query change away.
Re-ranking layer over the top-N chunks — cosine top-8 returns "most similar," not necessarily "most useful." A cross-encoder or MMR pass over a wider candidate set (top-30) would re-score for relevance and diversity, reducing the case where eight nearly-duplicate paragraphs crowd out genuinely different context.
Narrative SEC extraction beyond raw financials — extend ingestion to MD&A and Risk Factors so deep-tier prompts can lean on qualitative context that the structured tables don't capture.
Persistent PDF report storage tied to the watchlist — today reports generate on demand and disappear; persist them per ticker so past evaluations stay reachable from the user's watched list.
Finnhub fallback for non-US tickers — yfinance is inconsistent on international stocks; Finnhub provides standardized GAAP/IFRS data for the same tickers.