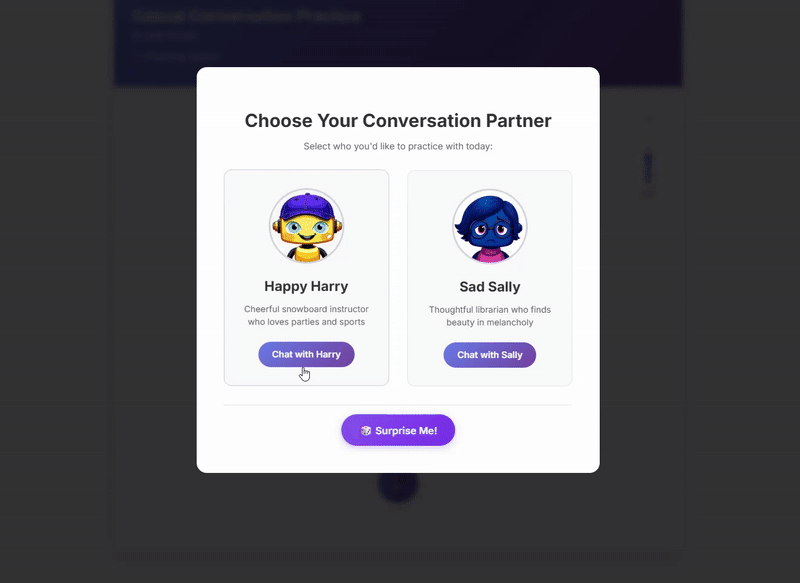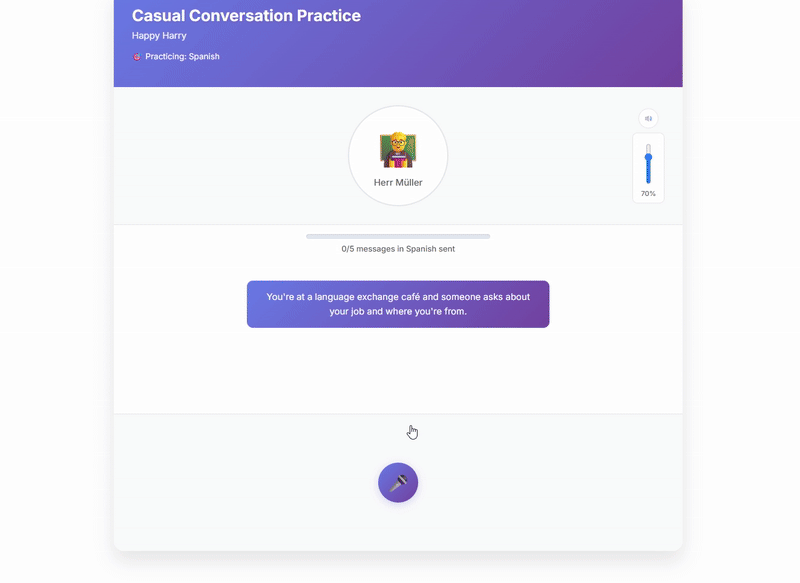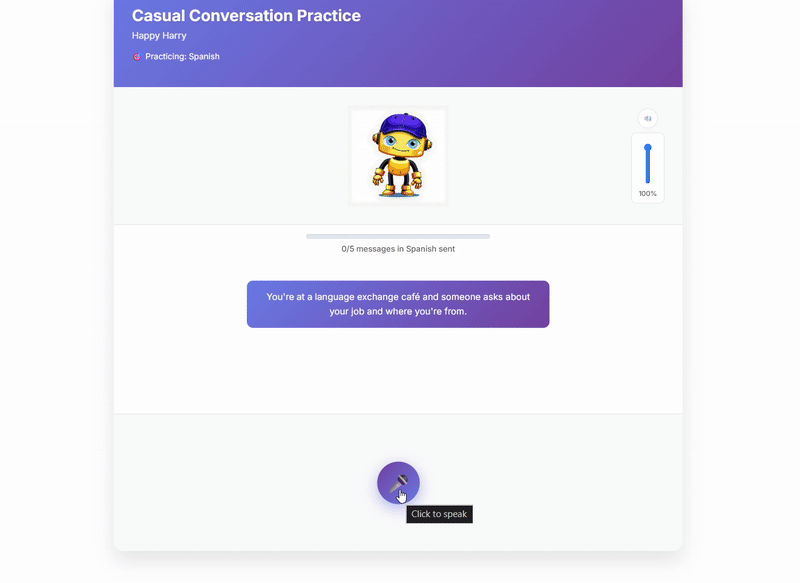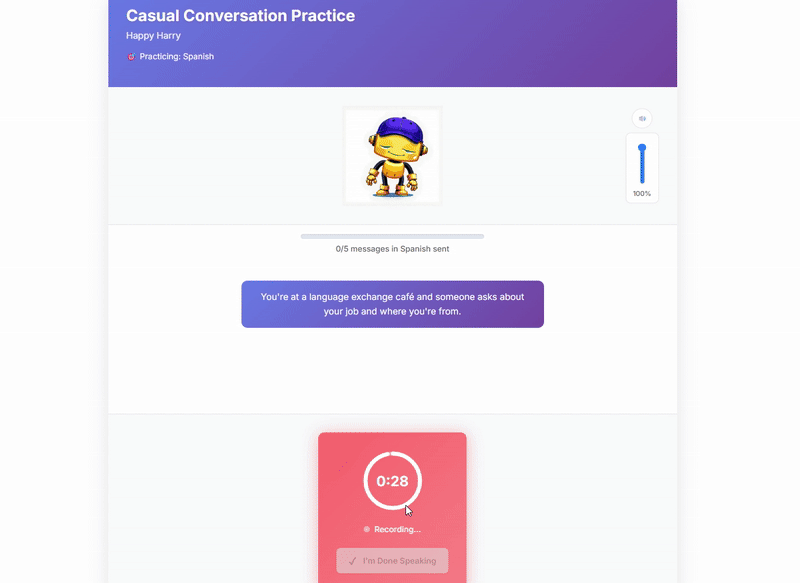
The Problem
Reading a language is one skill. Speaking it without freezing is a different one entirely.
Most apps drill vocabulary and matching exercises — useful for memorization, useless for the moment someone is waiting for you to reply out loud. That moment is gated by two things: latency (a typed exchange isn't the same exercise as a spoken one) and feedback (you need to know not just whether you made your point, but whether you were understandable). Spralingua V1 proved the conversation loop — request/response, browser speech recognition, a few sequential Claude calls per turn — but it couldn't stream, and it had no way to tell you how you did.
Spralingua V2 is a real-time voice agent. You talk, it talks back in under 2.5 seconds over a streaming WebSocket pipeline, and when the session ends it grades the conversation on two axes — did you complete the lesson's goals, and how was your pronunciation.
One-Minute Walkthrough
Video coming soon
A one-minute screen recording covering lesson and voice selection, a live spoken conversation with the streaming agent, and the post-session summary with goal and pronunciation scores.
System Design
A fresh Pipecat pipeline is assembled per client at WebSocket connect: STT → VAD-gated buffer → LLM → TTS, streaming audio in and out of the browser.
Every stateful piece — the agent, the STT and TTS sessions, the audio buffer, the logger — is instantiated inside the per-connection builder. There is no shared global pipeline, which is exactly what lets multiple users talk to the agent at the same time without their conversations crossing.
Three design choices worth discussing
A per-client pipeline, not a global agent. V1's biggest production bug was conversation state leaking across Gunicorn workers — I once opened my own session and saw a conversation I hadn't had. V2 makes that structurally impossible: connection state is born and dies inside run_pipeline(), scoped to one WebSocket. Multi-user isolation isn't a feature bolted on; it's a property of where the objects live.
VAD-gated buffering between speech recognition and the LLM. Streaming STT emits partial transcriptions continuously. Forwarding each one to the LLM produces fragmented, overlapping replies — the agent answers three times in a row. A converter sits between the two stages, clears its buffer when the user starts speaking, accumulates transcription text, and emits exactly one complete utterance to the LLM when Silero VAD detects 1.5 seconds of silence.
Clearing the buffer on speech-start is also the interruption-safety mechanism: stale partial text from a sentence the user abandoned is discarded instead of reaching the model.
Evaluation runs after the call, not during it. Both scorers — the goal evaluator and the Azure pronunciation pass — fire at disconnect, in their own non-fatal try/except blocks. Nothing about grading touches the live turn loop, so the sub-2.5-second pipeline TTFB stays clean while the user still gets a full scored summary seconds after they finish.
Browser (mic) Browser (speaker)
│ ▲
│ audio frames agent speech │
▼ │
┌──────────────────────── WebSocket (Pipecat) ───────────────────┐
│ │
│ Deepgram Nova-2 ──▶ VAD-gated buffer ──▶ Cerebras gpt-oss-120b │
│ (STT) (Silero 1.5s) (LangGraph agent) │
│ │ │
│ ▼ │
│ MiniMax 2.8-turbo (TTS) ──┘
│
└──────────────────────────────────────────────────────────────────
│ per-turn traces
▼
Langfuse v4 · Postgres (1 row / session)
│ at disconnect
▼
Goal evaluator (LLM judge) + Azure pronunciation
One per-client pipeline per WebSocket. Live loop stays in the box; scoring runs once the call ends.
Stack & Why
Four groups, each choice with a short note on the reasoning behind it. V2 answers the V1 roadmap, so several of these are the deliberate replacements for V1's "good enough for now" calls.
Backend
-
FastAPI + uvicorn, Python 3.12 (uv-managed) — an async runtime is non-negotiable for a per-client WebSocket pipeline. FastAPI accepts the socket and hands it straight to the pipeline builder; uvicorn carries the concurrent connections.
-
Pipecat 0.0.98 for the audio pipeline — the framework owns frame ordering and transport so the application code is just the stages and their adapters. The pipeline is the source of truth for ordering; components talk through frames, never side channels.
Frontend
-
Next.js 16 + React 19 + Tailwind CSS 4 + TypeScript — V1's vanilla-JS-on-Flask-templates frontend retires. A typed component tree makes the connection lifecycle (setup → briefing → live chat → scored summary) something you can reason about instead of a pile of event handlers.
-
@pipecat-ai/client-js over a WebSocket transport — the official client handles the WebSocketTransport + ProtobufFrameSerializer handshake, microphone capture, and audio playback. Bot text bubbles are revealed on a delay tied to the audio duration so the caption lands as the voice finishes, not before.
AI Layer
-
Deepgram Nova-2 for speech-to-text — V1 leaned on the browser's Web Speech API, which is free but uneven across browsers. Server-side STT makes the input half of the loop independent of which browser the user happens to open.
-
Cerebras
gpt-oss-120b via OpenRouter, on LangChain + LangGraph — the model is picked specifically for low-latency inference; conversation pace lives or dies on time-to-first-token. LangGraph carries a layered prompt middleware and an InMemorySaver keyed by user, and OpenRouter is pinned with provider.order=["cerebras"] so routing can't silently drift to a slower host.
-
MiniMax
speech-2.8-turbo for text-to-speech — the turbo tier favors latency over the HD tier's expressive range, and a VOICE_MAP picks the voice per session.
MiniMax's model and voice_id are constructor arguments on the TTS service, not fields on InputParams — putting them in InputParams silently falls back to the defaults, so you get audio in the wrong voice with no error.
-
Lessons as YAML, not code — one file per lesson under
agents/prompts/, branching on a type field (conversation for open practice, respond for scripted roleplay). Adding a lesson is dropping a file; the loader builds the path from the id. The same prompts-as-data habit started in V1 and carried through.
-
Cerebras again as the post-session goal judge — the evaluator is a single structured-output call (
.with_structured_output into a nested Pydantic model) that scores each lesson goal independently with evidence and reasoning.
Infrastructure & Data
-
PostgreSQL 18 + async SQLAlchemy 2 + asyncpg + Alembic — one row per WebSocket session in
activity_session, with evaluator results stored as JSONB and a frozen snapshot of the lesson YAML captured at connect so a later history view shows what the user actually saw. The startup is fail-loud: if Postgres is unreachable, the server exits rather than booting half-broken.
Alembic runs sync (psycopg2) while the app runs async (asyncpg); env.py swaps the driver in the DSN string before handing it to Alembic.
-
Langfuse v4 for per-turn observability — each turn opens its own trace with the STT, LLM, and TTS spans nested underneath, so every turn is independently inspectable for latency and cost.
The LangChain
CallbackHandler got dropped: it measures full-chain duration (request fired → last token), which is confounded by response length and can't answer "which stage was the bottleneck?" A hand-rolled span captures true time-to-first-token instead.
-
Azure AI Speech for pronunciation assessment — scripted-mode per-turn scoring (accuracy, fluency, completeness, prosody), run post-session against the Deepgram transcript as ground truth.
Evaluation
This is the largest reversal from V1, which had no evaluation layer at all — the eval pipeline was "I used the app and bugs surfaced." V2 measures itself on three levels.
1. Per-turn tracing — is the pipeline fast, and where's the time going?
Every turn is its own Langfuse trace, with the speech-recognition, LLM, and speech-synthesis spans nesting underneath. The turn span captures user-perceived turn time (user starts speaking → bot starts speaking, which honestly includes the unavoidable 1.5s VAD silence wait), while the narrower pipeline-only number is preserved as a separate attribute for the "how fast is our pipeline" question. Because the auto-instrumented chain handler conflated full duration with latency, the LLM span is hand-rolled to record actual time-to-first-token — the number that decides whether the conversation feels real-time.
2. Goal evaluation — did the student do what the lesson asked?
When the session closes, a single LLM judge (Cerebras gpt-oss-120b) scores the transcript against the lesson's goals. It returns a nested structured result — an overall score against a pass threshold, plus a per-goal verdict with an exact quote from the student as evidence and a one- or two-sentence rationale. The judge is instructed to pass an in-language attempt even with grammar errors, and to fail wrong-language, wrong-act, or no-attempt — competence at the speech act, not perfection.
3. Pronunciation assessment — how did they sound?
Azure AI Speech scores each user turn in scripted mode, pairing the captured audio with the Deepgram transcript as the reference text so omissions, insertions, and mispronunciations are flagged against ground truth. The summary modal is CEFR-level-aware: it leads with accuracy, then progressively surfaces fluency, completeness, and prosody at higher levels, and collapses per-word detail down to threshold-gated callouts so a beginner sees encouragement instead of a wall of red.
Audio and text come from two independent producers, so they're joined by a shared per-VAD-stop sequence number; orphan audio (a breath, a mic glitch, an STT miss) is dropped and counted rather than silently misaligning a score to the wrong turn.
Results
- Live at spralingua.com — the real-time voice loop runs end-to-end in production, streaming over a WebSocket from browser mic to browser speaker.
- Under 2.5 seconds time-to-first-byte on the live pipeline (user stops speaking → bot starts speaking), measured per turn in Langfuse.
- Multi-client by design — each connection runs an isolated pipeline, so concurrent users never share state. V1's worker-bleed bug is structurally gone.
- Two-axis scoring every session — goal completion via an LLM judge and pronunciation via Azure Speech, both persisted as JSONB on a single session row.
- Seven pronunciation locales available (en-US, de-DE, es-ES, es-MX, fr-FR, zh-CN, ja-JP), with CEFR A1 and B1 lessons live as YAML.
- Every V1 roadmap item shipped — streaming voice loop, server-side speech recognition, a faster conversation-pace model, and production observability from day one. The
print()-logs era is over.
Roadmap
- Authentication and a per-user data model — the user id is hardcoded today while the prompt and LLM layers are still being iterated; real accounts land once that design settles.
- More lessons and levels — A2 and B2 situations, additive at the YAML layer with no loader changes.
- WebSocket reconnection — today a dropped connection or a changed selector means a fresh connect; graceful reconnection is next.
- Character voices cloned from real recordings — moving beyond preset MiniMax voices to identities you might recognize.
- Voice or text, your call — speaking stays the headline mode, with typed input alongside it for accessibility and quieter environments.