The Problem
YouTube is one of the best places to learn — but learning from it is slow.
A 40-minute talk hides 5 minutes of substance, and the language barrier makes the cost higher: if the talk you need is in a language you don't speak, you either skip it or sit through machine-translated captions that miss the nuance.
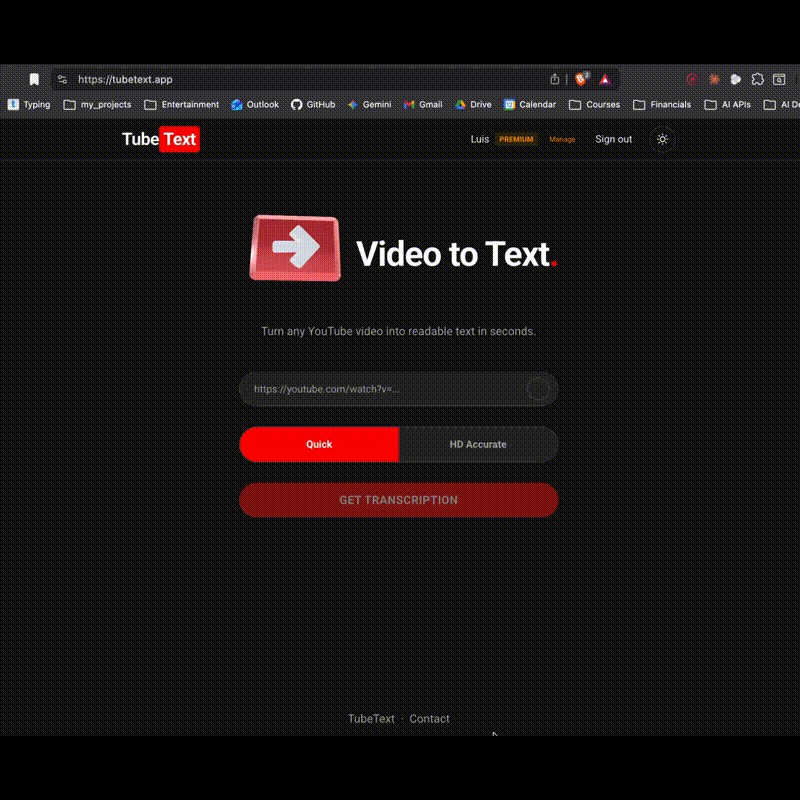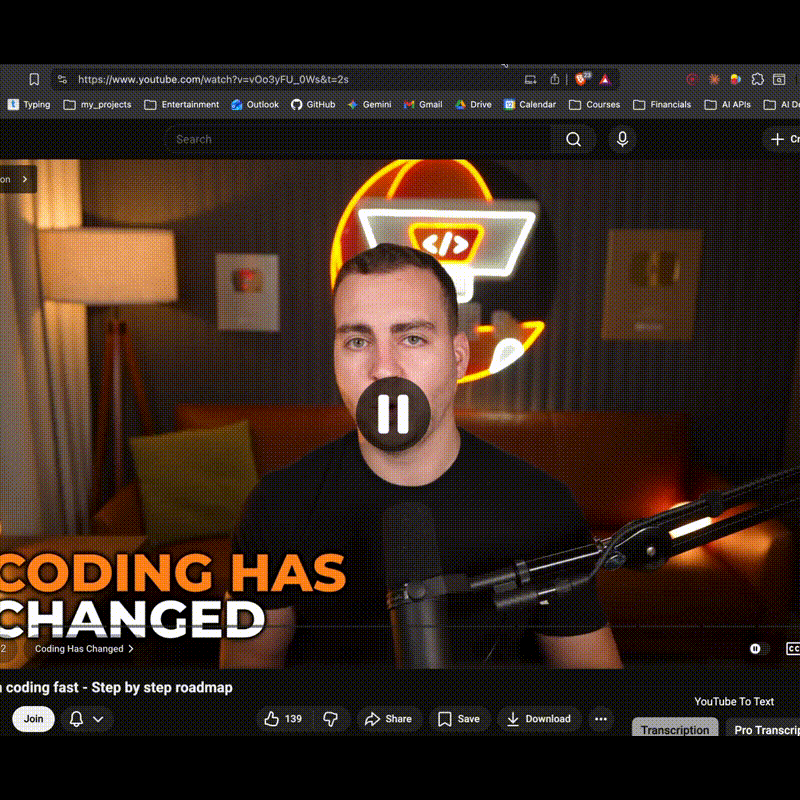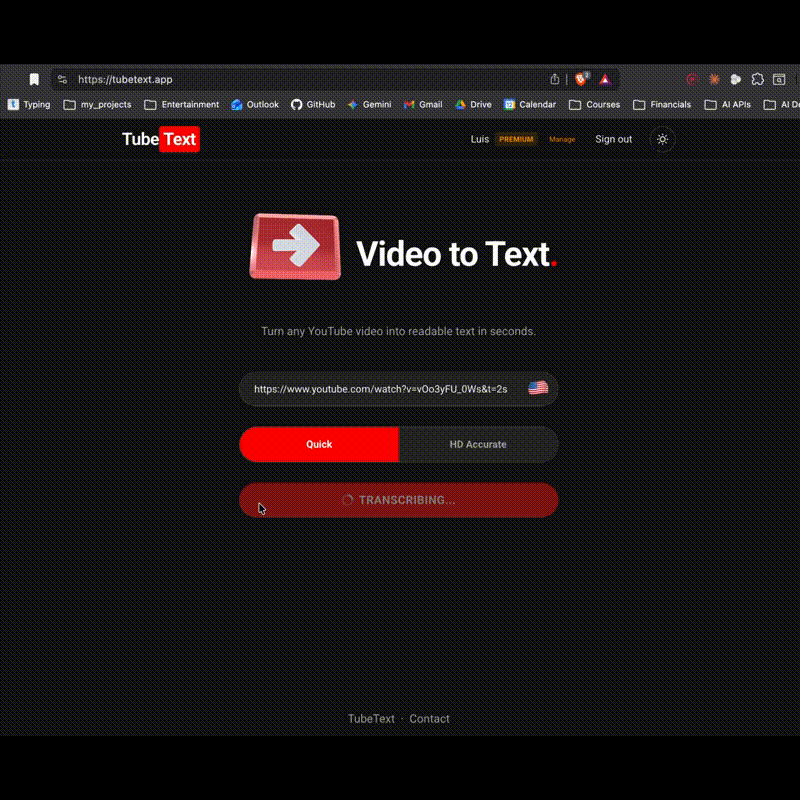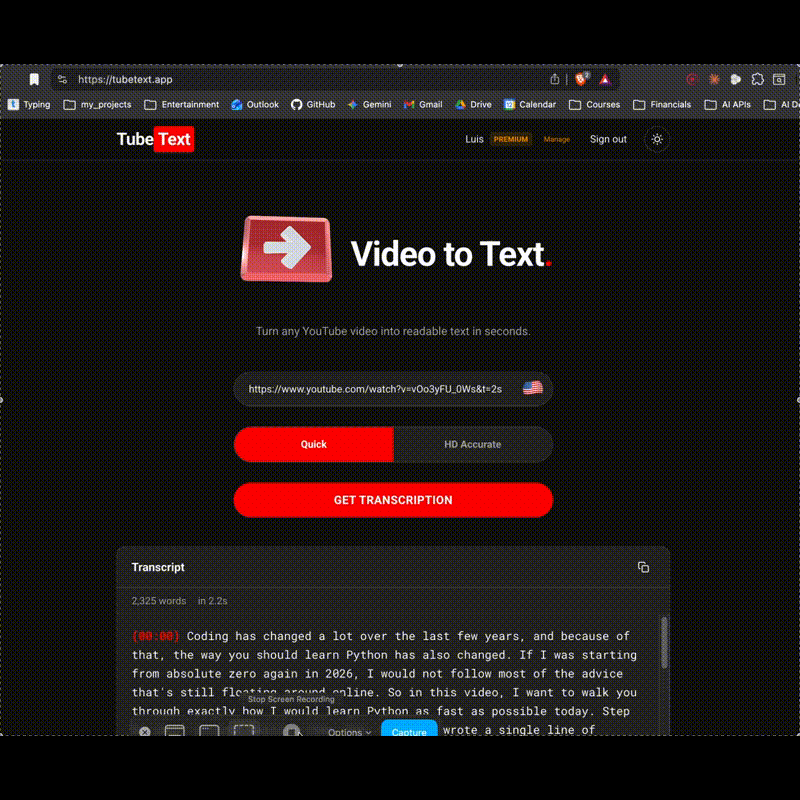
TubeText turns any YouTube video into a structured transcript, a focused summary, and a translation in 20+ languages. Watch what matters, in the language you read fastest.
One-Minute Walkthrough
Video coming soon
A one-minute screen recording covering the four flows: free transcript, premium transcript, summary, translation.
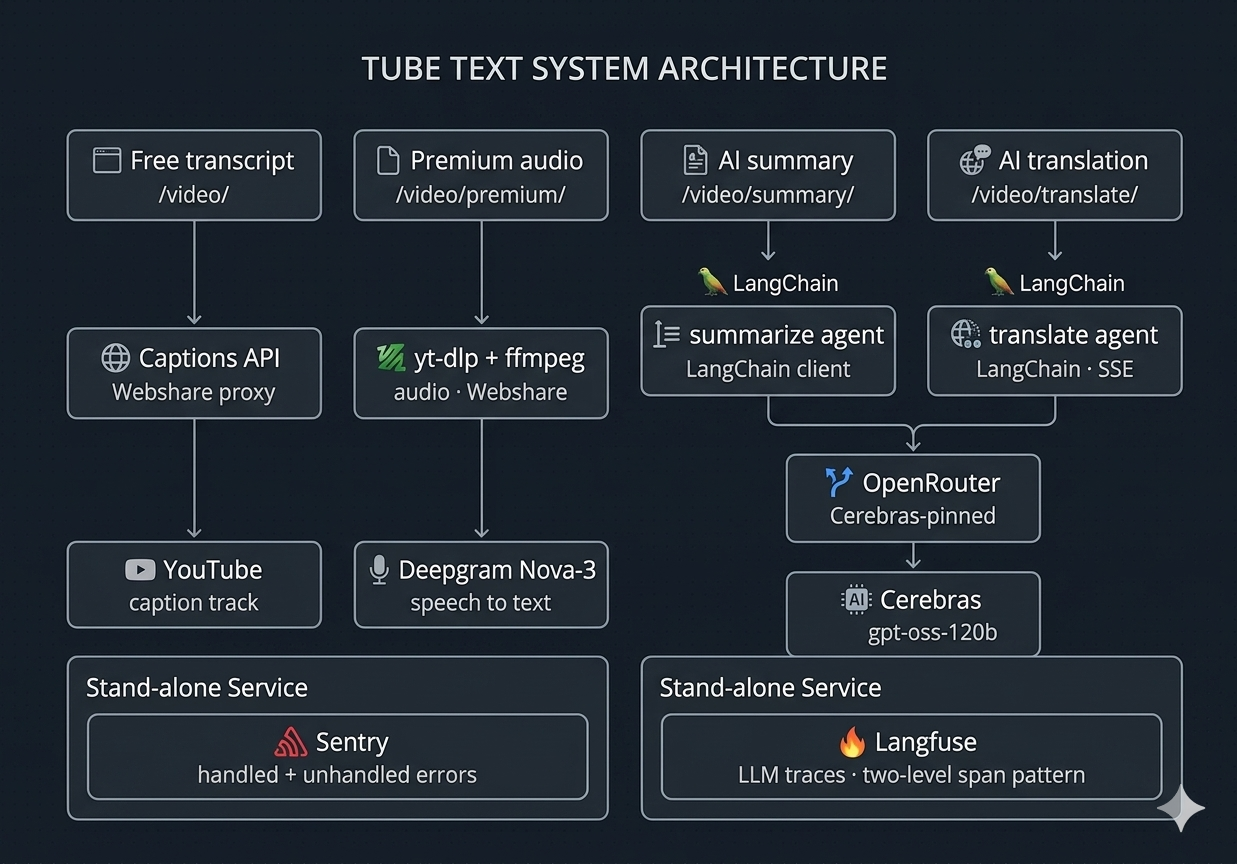
System Design
One FastAPI service. Four pipelines. Every call traced end-to-end through Langfuse.
No event queue, no worker pool — the async runtime handles current scale on its own, with asyncio.to_thread bridging the sync SDKs (yt-dlp, Deepgram) into the async stack.
Three design choices worth discussing
Residential proxy + error classification, not naive retry. YouTube blocks cloud IPs aggressively. Every request routes through Webshare's rotating residential pool, and exceptions from both youtube-transcript-api and yt-dlp are classified into five buckets: transient, no_captions, unavailable, bad_input, unknown. Only transient retries; the rest map to user-facing messages ("try Premium", "video is private") instead of generic failure.
Async orchestration with bounded retry budgets. The free path retries 3 times with (0.5s, 1s, 2s) backoff because each attempt is cheap. The premium path retries only 2 times with 3s backoff because each attempt is 30–90s of yt-dlp + Deepgram work — same pattern, different budget.
Three-tier freemium without DB pollution. Anonymous users (5 videos/month) are tracked by a signed HTTP-only cookie. Zero database writes until they create an account — saves storage and avoids "what do we do with abandoned anonymous data?" questions cleanly.
Stack & Why
Four groups, each choice with a short note on the reasoning behind it.
Backend
-
Python 3.12 — the AI ecosystem is built here. Every provider (Deepgram, OpenAI, Cerebras, OpenRouter, LangChain) ships a first-class Python SDK, and async/await + Pydantic cover concurrency and types without a second language in the stack.
-
FastAPI — native async + Pydantic schemas means request/response models are defined once, not twice. Endpoint typing flows through to OpenAPI docs for free.
-
PostgreSQL + async SQLAlchemy 2.0 + Alembic — one data store, no Redis cache layer to maintain. Alembic gives reviewable migrations (4 versions so far).
Frontend
-
Next.js 16 + React 19 + TypeScript — SSR for SEO on the landing page; React 19 transitions for the SSE translation UI so chunks render without jank as they stream in. TypeScript end-to-end so the API contract is enforced from request to render.
AI Layer
-
Deepgram Nova-3 for premium transcription — YouTube captions are missing on ~20% of videos. Nova-3 outperforms Whisper-large on noisy audio at predictable per-second pricing ($0.0000723/s, empirically derived from invoices and baked into Langfuse cost rollups).
-
OpenRouter as LLM gateway, pinned to Cerebras — one API key, one billing dashboard, swap providers via env var. Cerebras delivers ~10× the throughput of standard endpoints — matters because translation streams chunk-by-chunk over SSE and latency per chunk is user-visible.
-
openai/gpt-oss-120b for summary and translation — strong instruction-following at a fraction of GPT-4 cost; one model for both keeps prompts and evaluation consistent.
-
YAML-driven prompts — prompts live in
agents/prompts.yaml, separated from application logic. Iteration doesn't require code changes.
Infrastructure & Auth
-
Server-Sent Events for translation streaming — simpler than WebSockets for one-way data flow.
Once HTTP 200 is sent you can't return error status mid-stream, so error events are part of the stream protocol — the frontend listens for
{"error": ...} payloads, not HTTP codes.
-
JWT in HTTP-only cookies (Google OAuth) — XSS-safe, browser sends automatically, no password storage to maintain.
Behind Railway's reverse proxy, FastAPI generated
http:// redirect URIs and Google rejected with redirect_uri_mismatch. Fixed with ProxyHeadersMiddleware reading X-Forwarded-Proto.
-
Stripe Checkout + webhooks — webhooks as source of truth. Lifetime purchases identified as
status=active with subscription_id=null.
-
Webshare residential proxy —
-rotate username suffix gives per-request IP rotation, defeats YouTube's cloud-IP blocks without managing an IP pool myself.
-
Docker + Railway (3 services) — PostgreSQL, backend, frontend on one platform. No Kubernetes complexity for a three-service app.
-
Sentry for non-AI error capture — pairs with Langfuse, which covers the AI side. Two systems by design: LLM calls and their costs go to Langfuse, everything else (HTTP errors, unhandled exceptions, deploy regressions) goes to Sentry. Different signal types, kept on different dashboards.
Evaluation
Three layers of observability run in production. This is the part most AI portfolio projects skip — and the part interviewers actually want to ask about.
1. Langfuse traces — every call, every cost
A two-level trace pattern wraps every user action:
- Outer span = the user-facing action (transcript / summary / translation) with judge-readable
input and output text, plus metadata: user_id, language tag, tier tag.
- Inner generation = the LLM call itself, with token counts and cost (from OpenRouter's API response, or a hardcoded rate for Deepgram).
Why two levels: LLM judges need plain text I/O at the top, not nested chunk-level logs. The outer span is the user's action; the inner generation has the cost details. Costs roll up from inner to outer automatically — margin per request is visible in Langfuse, not a spreadsheet.
2. LLM-as-judge — adequacy on translations
Configured in the Langfuse UI, an adequacy judge runs on every translation trace. The judge is openai/gpt-4o-mini via OpenRouter, and it walks an idea-by-idea checklist over source vs. translation — each idea labelled PRESERVED, MISSING, DISTORTED, or ADDED — producing a 1–5 score plus written reasoning.
What this catches that BLEU and ROUGE don't: hallucinated additions, dropped sentences, register shifts. A summary-faithfulness judge is wired on the same pattern, pending UI activation.
3. Human feedback — sampled, idempotent, attached to traces
The frontend shows a thumbs prompt on 10% of outputs (configurable, to avoid feedback fatigue). Submissions write a Langfuse score with an idempotent ID — {trace_id}:{name} — so resubmits upsert instead of duplicate. Thumbs-down comments (up to 500 chars) flow into the trace as searchable feedback, and a per-IP rate limit (30 / 5 min) blocks spam without forcing an auth wall.
Sessions — per-video cohort analysis
On top of the three layers above, sessions group everything by source video. The frontend generates a crypto.randomUUID() per YouTube URL; the backend attaches it via an X-Session-Id header. All three premium outputs (transcript / summary / translation) for the same video roll up into one Langfuse Session — letting me answer "did this video produce a bad transcript and a bad summary, or just one of them?" instead of guessing.
Results
- Live with paying users. Stripe Checkout across three plans: €5/month, €49/year, €79 lifetime.
- Three-tier freemium. Anonymous (5 videos/month, cookie-tracked, zero DB rows), free (20/month), premium (unlimited).
- 20+ target languages supported, four currently surfaced in the production UI (Spanish, Portuguese, German, French). Expansion gated on adequacy-judge scores per language — if the judge says quality is shaky, the language doesn't ship.
- End-to-end cost visibility per request. Deepgram + OpenRouter costs roll up to the parent span; tier margin is visible in Langfuse.
- Async pipeline holds under load despite sync-SDK bridges; no event queue needed at current scale.
Roadmap
- Summary-faithfulness judge — second LLM-as-judge for the summary endpoint. Judge prompt drafted, pending Langfuse UI activation.
- Chained workflows — summarize from a translation, translate from a summary. Today each action restarts from the transcript.
- Batch transcription — playlists and per-creator search — expand from single video to entire YouTube playlists, and let users transcribe everything a given creator has uploaded. One workflow handles many.
- User action history — a personal database of videos done, summaries generated, and translations completed. Lets users revisit past work, re-export, and build on it instead of restarting each session.
- Move yt-dlp + Deepgram off the request path — background worker so a FastAPI worker doesn't hold a connection for 60+ seconds on long videos.
- ISO-code standardization across summary and translate APIs — today the summary endpoint uses ISO codes and the translate endpoint uses display names. Internal consistency, easier to extend.